10 Things to Know About Docker

It’s possible that containers and container management tools like Docker will be the single most important thing to happen to the data center since the mainstream adoption of hardware virtualization in the 90s. In the past 12 months, the technology has matured beyond powering large-scale startups like Twitter and Yelp and found its way into the data centers of major banks, retailers and even NASA. When I first heard about Docker a couple years ago, I started off as a skeptic. I blew it off as skillful marketing hype around an old concept of Linux containers. But after incorporating it successfully into several projects at Spantree I am now a convert. It’s saved my team an enormous amount of time, money and headaches and has become the underpinning of our technical stack.
If you’re anything like me, you’re often time crunched and may not have a chance to check out every shiny new toy that blows up on Github overnight. So this article is an attempt to quickly impart 10 nuggets of wisdom that will help you understand what Docker is and why it’s useful.
Docker is a container management tool.
Docker is an engine designed to help you build, ship and execute applications stacks and services as lightweight, portable and isolated containers. The Docker engine sits directly on top of the host operating system. Its containers share the kernel and hardware of the host machine with roughly the same overhead as processes launched directly on the host machine.
But Docker itself isn’t a container system, it merely piggybacks off the existing container facilities baked into the OS, such as LXC on Linux. These container facilities have been baked into operating systems for many years, but Docker provides a much friendlier image management and deployment system for working with these features.
Docker is not a hardware virtualization engine.
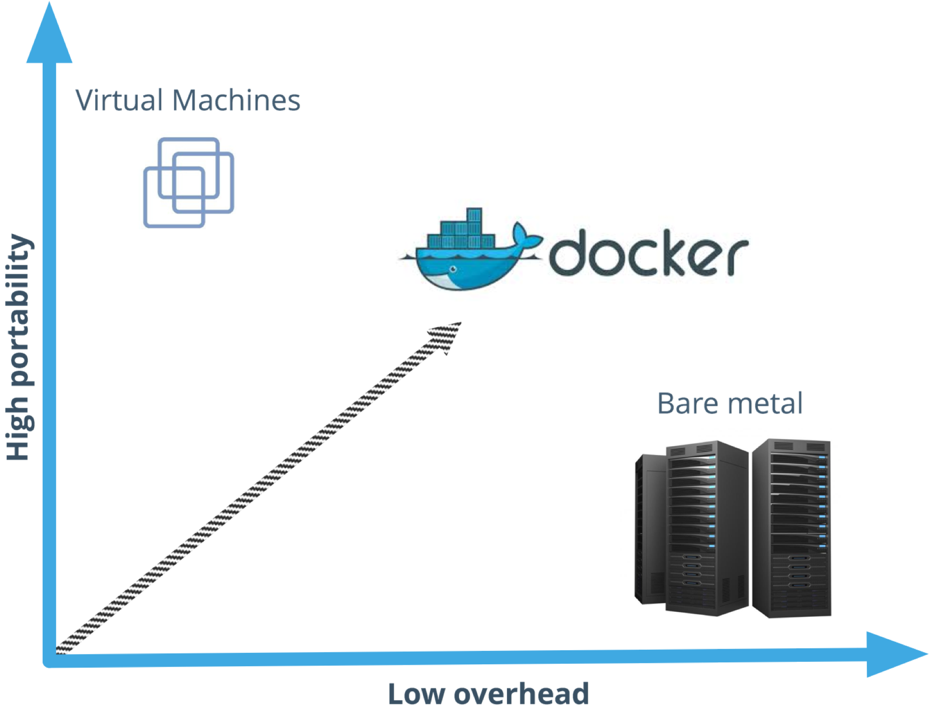
When Docker was first released, many people compared it to virtual machine hypervisors like VMWare, KVM and Virtualbox. While Docker solves a lot of the same problems and shares many of the same advantages as hypervisors, Docker takes a very different approach. Virtual machines emulate hardware. In other words, when you launch a VM and run a program that hits disk, its generally talking to a "virtual" disk. When you run a CPU-intensive task, those CPU commands need to be translated to something the host CPU understands. All these abstractions come at a cost: two disk layers, two network layers, two processor schedulers, even two whole operating systems that need to be loaded into memory. These limitations typically mean you can only run a few virtual machines on a given piece of hardware before you start to see an unpleasant amount of overhead and churn. On the other hand, you can theoretically run hundreds of Docker containers on the same host machine without issue.
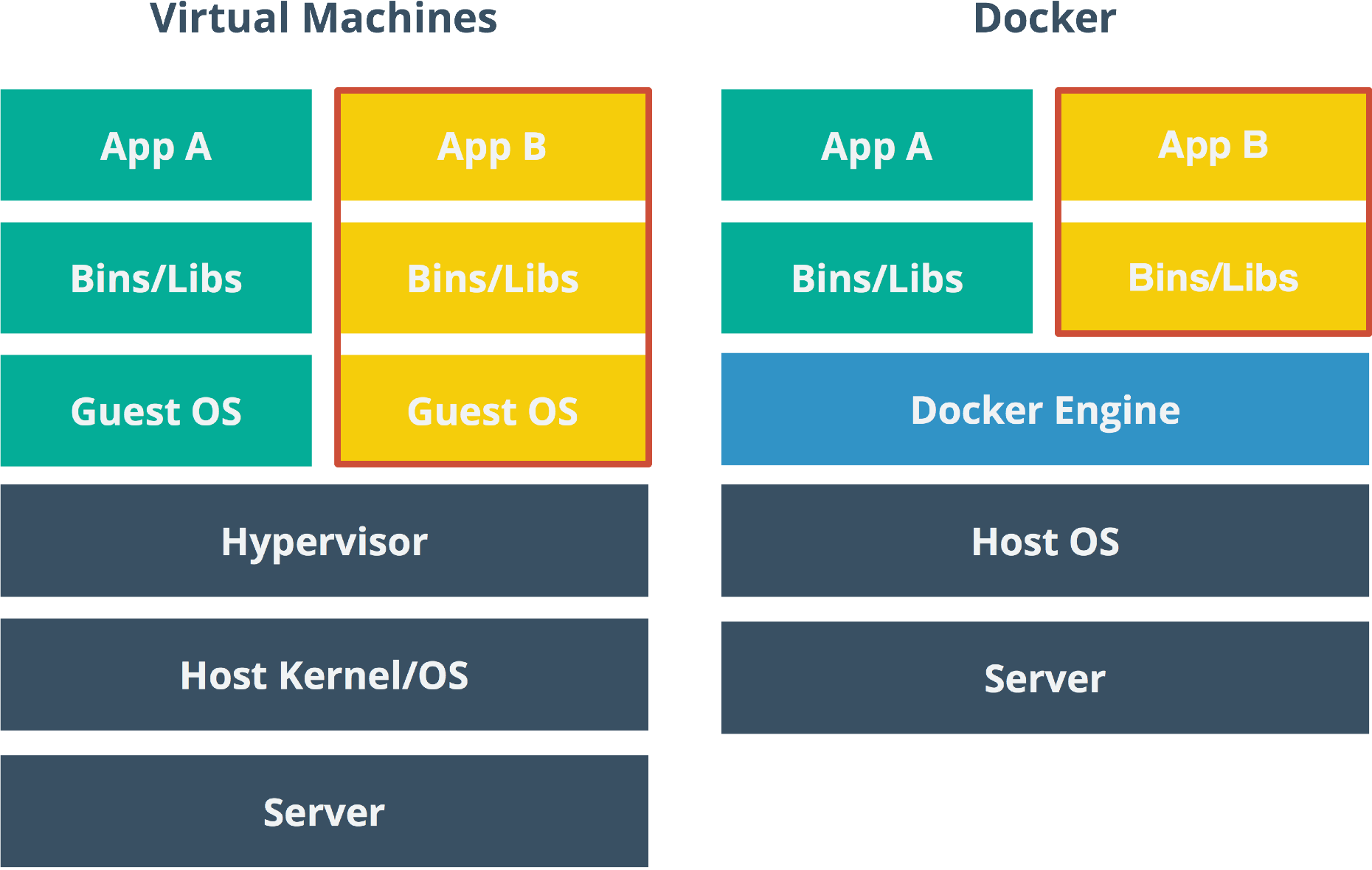
All that being said, containers aren’t a wholesale replacement for virtual machines. Virtual machines provide a tremendous amount of flexibility in areas where containers generally can’t. For example, if you want to run a Linux guest operating system on top of a Windows host, that’s where virtual machines shine.
Docker uses a layered file system.
As mentioned earlier, one of the key design goals for Docker is to provide image management on top of existing container technology. In Docker terms, an image is a static, immutable snapshot of a container’s file system. But Docker rather cleverly takes this snapshotting concept a step further by incorporating a copy-on-write filesystem into its design. If you've ever used photoshop before, then the concept of layers may already be familiar. Essentially, edits to one layer do not directly affect the layers below. I’ve found the best way to explain this is by example...
Let’s say you want to build a Docker image to run your Java web application, for example. You may start with one of the official Docker base images that have Java 8 pre-installed. In your Dockerfile (a text file which tells Docker how to build your image) you’d specify that you’re extending the Java 8 image, which instructs Docker to pull down the pre-built snapshot associated with this image. Now, let’s say you execute a command that downloads, extracts and configures Apache Tomcat into /opt/tomcat. This command will not affect the state of original Java 8 image. Instead, it will start writing to a brand new filesystem layer. When a container boots up, it will merge these file systems together. It may load /usr/bin/java from one layer and /opt/tomcat/bin from another. In fact, every step in a Dockerfile produces a new filesystem layer, even if only one file is changed. If you’re familiar with the Git version control system, this is similar to a commit tree. But with Docker, it provides users with tremendous flexibility to compose application stacks iteratively.

At Spantree, we have a base image with Tomcat pre-installed and on each application release we merely copy the latest deployable asset into a new image, tagging the Docker image to match the release version as well. Since the only variation on these images is the very last layer, a 90MB WAR file in our case, each image is able to share the same ancestors on disk. This means we can keep our old images around and rollback on-demand with very little added cost. Furthermore, when we launch several instances of these applications side-by-side, they share the same read-only filesystems.
Docker layers are defined in a Dockerfile.
Dockerfiles are text files that provide the Docker engine with build instructions. Essentially, these instructions line up neatly with the commands you'd run manually to set up an application on a bare metal machine. Dockerfiles also define a parent image. Parent images can be a base image, which contains only packaged libraries from a Linux distribution, but parent images can also be any valid image available to the Docker engine (e.g. spantree/ubuntu-oraclejdk8.
To achieve the Tomcat build described earlier, we might create two Docker images built from the following Dockerfiles:
spantree-ubuntu-oraclejdk-8/Dockerfile:
loading
spantree-awesome-tomcat-app/Dockerfile:
loading
You may notice that some RUN statements contain a series of chained commands. We often do this because Docker will take a snapshot of filesystem changes after every build step. To keep our layer images as small as possible, we try to clean up after ourselves in the same step to remove any temporary files we don't needed at runtime (e.g. tomcat.tar.gz). If you're curious to learn more, Sebastian posted a great blog article with more tips for writing Dockerfiles.
Docker can prevent greedy processes from eating your machine.
In addition to LXC, Docker also makes use of cgroups, another Linux kernel feature that allows systems to isolate and limit the CPU, memory, disk and network resources a process can use. With Docker, you can achieve these via runtime constraints when you start up an image. This benefit is leveraged heavily by scheduling frameworks like Apache Mesos when distributing jobs across a cluster. We recorded a screencast a few months ago which demonstrates this approach in action:
In addition to cgroups, a related feature called kernel namespaces allow Docker to narrowly restrict which processes a running container has access to. Inside the container, a process may think its the only other process running on the machine, getting a process id of 1 inside the namespace. Namespaces give you the flexibility to run untrusted code in a sandbox, similar to the way modern browsers like Google Chrome isolate running code between browser tabs. However, if you're looking to run truly secure and isolated workloads, be sure you're aware of the caveats.
Docker can save you time.
Many years ago, I was working on a project for a major restaurant chain and on the first day I was handed a 12 page Word document describing how to get my development environment set up to develop against all the various applications. I had to install a local Oracle database, a specific version of the Java runtime, along with a number of other system and library dependencies and tooling. The whole setup process cost each member of my team approximately a day of productivity, which unfortunately translated to thousands of dollars in sunk costs for our client. Our client was used to this and considered this part of the cost of doing business when onboarding new team members, but as consultants we would have much rather spent that time building useful features that add value to our client’s business.
Had Docker existed at the time, we could have cut this process from a day to mere minutes. With Docker, you can express servers and services through code, similarly to configuration tools like Puppet, Chef, Salt and Ansible. But, unlike these tools, Docker goes a step further by actually pre-executing these steps for you during its build process snapshotting the output as an indexed, shareable disk image. Need to compile Node.js from source? No problem. The Docker runtime will do that on build and simply snapshot the output for you at the end. Furthermore, because Docker containers sit directly on top of the Linux kernel, there’s no risk of environmental variations getting in the way.
Nowadays, when we bring a new team member into a client project, they merely have to run docker-compose up, grab a cup of coffee and by the time they’re back they should have everything they need to start working.
Docker can save you money.
Of course, time is money, but Docker can also save you hard, physical dollars as it relates to infrastructure costs. Studies at Gartner and McKinsey cite the average data center utilization at somewhere between 6 to 12%. Quite a lot of that underutilized space is due to static partitioning. With physical machines or even hypervisors, you need to defensively provision the CPU, disk and memory based on the high watermark of possible usage. Containers, on the other hand, allow you to share unused memory and disk between instances. This allows you to pack many more services onto the same hardware, spinning them down when they’re not needed without worrying about the cost of bringing them back up again. If it’s 3am and no one is hitting your Dockerized intranet application but you need a little extra horsepower for your Dockerized nightly batch job, you can simply swap some resources between the two applications running on common infrastructure.
Docker has a robust ecosystem of existing images.
At the time of writing, there are over 14,000 public Docker images available on the web. Most of these images are shared through Docker Hub. Similar to how Github has largely become the home of most major open-source projects, Docker Hub is the de facto resource for sharing and working with public Docker images. These images can serve as building blocks for your application or database services. Want to test drive the latest version of that hot new graph database you’ve been hearing about? Someone’s probably already gone to the trouble of Dockerizing it. Need to build and host a simple Rails application with a special version of Ruby? It’s now at your fingertips in a single command.
Docker helps you avoid production bugs.
At Spantree, we’re big fans of immutable infrastructure. That is to say, if at all possible, we avoid doing upgrades or changes on live servers at all costs. Instead, we build out new servers from scratch, applying the new application code directly to a pristine image and rolling the new release servers into the load balancer when they’re ready, retiring the old server instances after all our health checks pass. This gives us the ability to cleanly roll back if something goes wrong. It also gives us the ability to promote the same master images from dev to QA to production with no risk of configuration drift. By extending this approach all the way to the developer machine with Docker, we can also avoid the "it works on my machine" problem because each developer is able to test their build locally in a parallel
Docker only works on Linux (for now).
The technologies powering Docker are not necessarily new but many of them, like LXC and cgroups, are specific to the Linux kernel. This means that, at the time of writing, Docker is only capable of hosting applications and services that can run on Linux. That is likely to change in the coming years as Microsoft has recently announced plans for first-class container support in the next version of Windows Server, which was demoed in the keynote of their Build 2015 conference. Microsoft has been working closely with Docker to achieve this goal. In the meantime, tools like boot2docker and Docker Machine make it possible to run and proxy docker commands to a lightweight linux VM on Mac and Windows environments.