Bootstrapping the Web with Scala Native (Part 1)

Scala Native has advanced significantly since I last wrote about it, including a new garbage collector and substantially broader coverage on POSIX and JDK bindings. In terms of use cases, it's making rapid progress on command-line tools like scalafmt, and even scalac itself.
On the other hand, building something like a back-end REST API remains something of a frontier. In this post, I'll begin to explore some improvised approaches to web programming with Scala Native, and show some performance benchmarks to assess the robustness of my approach.
One caveat: everything I show here and in the Github repo is very rough, research-grade code, and there are still some really rough parts. I expect to smooth those out and clean up the API once I have a validated architecture, but for now the entire project should be considered highly experimental. Most importantly of all, any instability, impediment, or limitation should be ascribed to the quality of my code, infrastructure, and architecture, not to Scala Native itself.
Getting to the Web
So, to reframe the topic of this post: what can we do with Scala Native, and why is it not immediately obvious how to set up a web application? As noted above, Scala Native has excellent C/POSIX interop, as well as implementations of a subset of the standard JDK libraries, although not enough to substitute for a servlet container like Tomcat or Jetty. Which is to say: if we want to build a web app in Scala Native, we're stuck with POSIX, and POSIX network programming can be very, very hard.
We often forget this because most of the newer programming languages, frameworks, and platforms in wide use today -- Java, .NET, Go, Node -- provide robust web server capabilities out of the box, and most others have an ecosystem of application servers with standard interfaces, e.g., Rack for Ruby and WSGI for Python. But these sorts of capabilities can take many person-years of engineering time to stabilize, and many otherwise mature languages never make the leap.
At this point, an astute reader might ask: "why isn't there a generic interface for mounting HTTP services, separate from any particular platform implementation"? And indeed, there are projects that attempt just that -- one of my current favorites is Alex Ellis' FaaS (Functions as a Service) project, which provides a lightweight wrapper around any Docker container. However, this sort of generic application-gateway pattern is at least old as the web itself, and there's even an IETF specification, RFC 3875, that can mount any script or executable as a service over HTTP; you may know it better as the Common Gateway Interface, or CGI.
Handling Requests with CGI
Any web server can implement CGI, but it was much more common in older servers popular in the 90's, such as the venerable Apache httpd, and rarely implemented by newer servers like nginx. Typically, a server has a special directory in its document hierarchy, full of scripts or executables, as well as some configuration mechanism for routing different request URL's to those scripts. When a request is received that routes to a script:
- The server creates a new instance of the script to handle the request, typically with fork() and exec()
- The script receives the request URL and other metadata as environment variables
- If a request body is present, e.g., a POST request with form data, it is piped into the script's STDIN file handle
- The script processes these inputs and writes it's response out to STDOUT, including HTTP headers.
- The script terminates.
This approach has both benefits and drawbacks. Because each request has a dedicated process, there is no shared or persistent state, and none of the challenging concurrent programming issues that arise in such architectures. Because there is no run-time linkage between the server and the handler, any language can implement the handler protocol -- C, perl, bash, and awk were all common at one point. And best of all, the programming model is extremely straightforward, just read STDIN and write to STDOUT.
In my implementation, I can build up a chain of route handlers like so:
loadingAnd then matching inbound requests against those handlers is straightforward with Scala's pattern-matching capabilities:
loadingSo what are the downsides of this approach? Again, there is no shared or persistent state, with all the limitations that go with that. More concerning, we have to create a brand-new process for each HTTP request. With a C program or a lightweight script, this can be pretty minimal, typically a few tens of milliseconds to fork and load an executable. With a more "modern" platform like Ruby or Java, however, starting up a virtual machine and loading in dependencies can take seconds, which is completely unacceptable.
Fortunately for us, Scala Native's compact binaries behave much more like C, so we should at least test it out and see what we have to work with. If you look in the repository, you can see how to package a Scala Native executable with Apache in a single Dockerfile for a compact, self contained distribution -- but since that's mostly an elaboration on the technique described in my last blog post, I won't go into any more detail here. Instead, let's move on to some benchmarks.
Measuring Performance
Comparing the performance of various web servers is almost always controversial. Benchmarks that compare the performance of dozens of servers, in terms of response time or requests per second, generally privilege servers that are highly optimized for trivial loads. Worse, a metric like "mean response time" can hide a lot of important information; a service that times out 1% of the time can fail heartbeats and cause cascading failures in a modern cluster.
In an attempt to holistically characterize performance under load, I've measured 3 dimensions:
- 50th percentile (median) response time
- 99th percentile response time
- Maximum response time
I've used a Scala-based tool called Gatling to simulate the loads, and a Python library called Bokeh to chart the result. The load simulation, results, and plotting code are all in the repo. For now, I'm running everything on my laptop, but I'd like to do a more controlled run on dedicated EC2 boxes for a future post.
For a baseline, I ran a trivial python-based CGI app with apache. The results look like this:
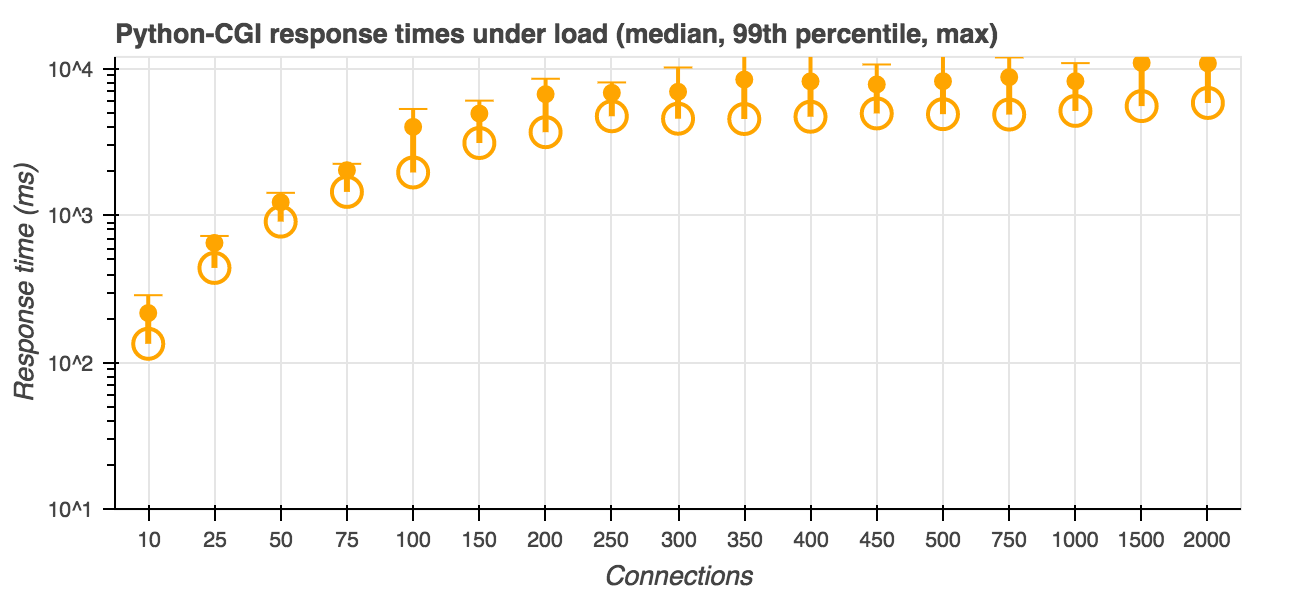
Which is, honestly, not great. The median response time is 136ms at 10 simultaneous users, goes above one second with 75 users, and becomes basically unusable beyond 150 users or so.
In contrast, here's Scala Native with Apache:
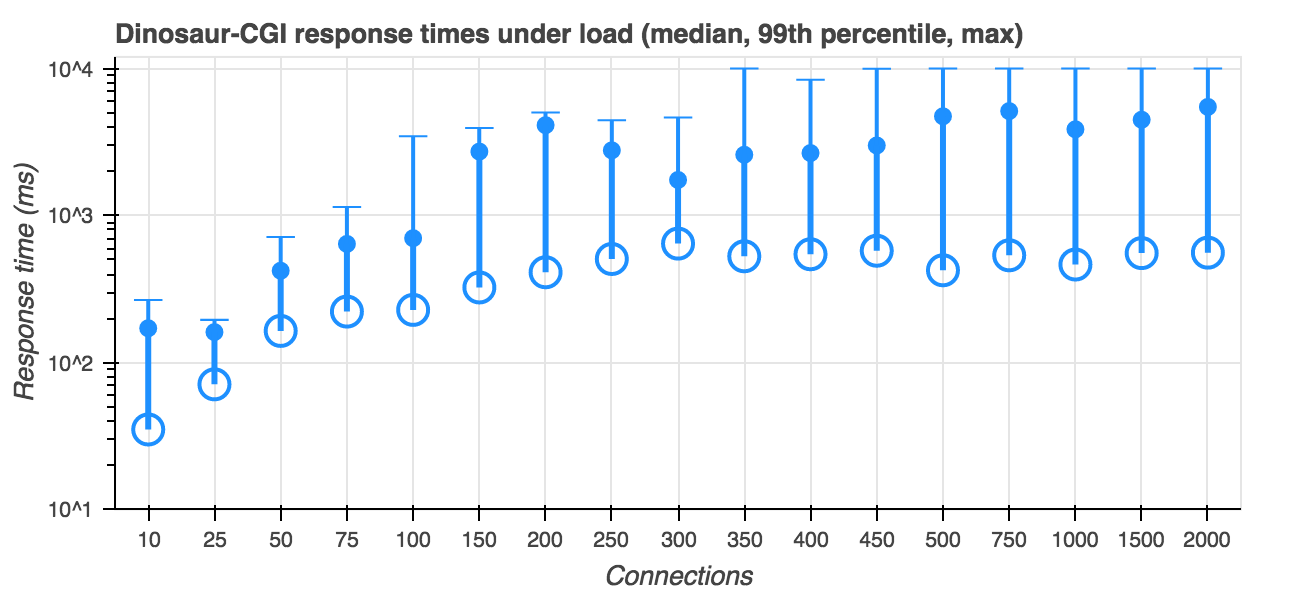
Which is substantially better, with typical response times ranging from 40-100ms under light load; but as we go past 100 users the worst-case response go up toward 5 seconds, and then begin to time out at 10 seconds with 350 users and up. With some more work to harden Apache, this could be entirely usable for low-traffic sidecar services like health checks and metrics scrapers. That being said, it's also clear that we can get much better performance out of another approach.
For comparison, I ran the same test suite on Node.js, which is generally outstanding at this sort of thing:
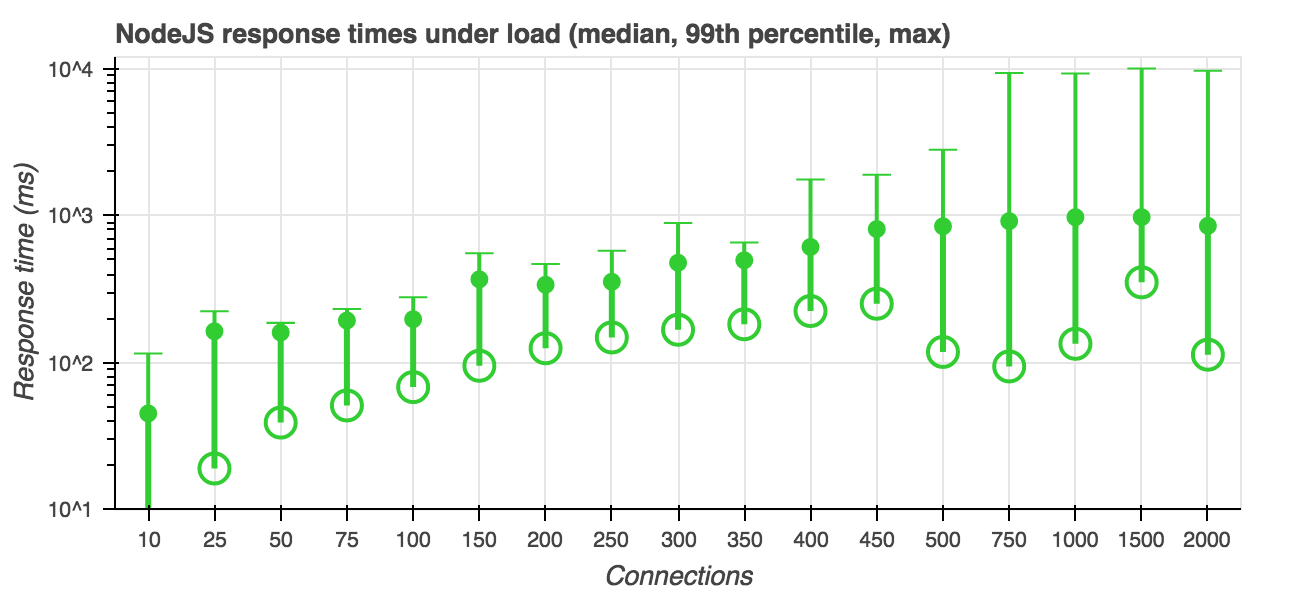
Indeed, under light load, the median response times are literally "off the charts" at 7 ms, maintaining superior performance until timeouts start to become a serious problem around 750 simultaneous users.
Next Steps
This leads us to the question: "why is Node so much faster than Apache?" The biggest difference is architectural: node handles all requests in a single process, and uses asynchronous IO to handle multiple concurrent requests. Indeed, node's approach is substantially faster than Apache itself, without Scala Native or any application code running at all, which leads us to wonder how our Scala Native application would perform with a similar approach to concurrency.
In the next post in this series, we'll start to close the gap, using nginx, request multiplexing, and binary protocols, but if anyone's curious now, a partial implementation is in the repository. In the meantime, don't hesitate to reach out on Twitter @RichardWhaling if you have questions or comments!